AlphaGo勝棋王靠直覺?幕後工程師解密






【新唐人亞太台 2016 年 03 月 18 日訊】歡迎回來,人機大戰 谷歌AlphaGo的幕後功臣,台灣博士黃士傑今天回到台灣,和外界分享人工智慧演進關鍵,帶您來看看。
AlphaGo 人工智慧,4比1戰勝韓國棋王,AlphaGo主要程式開發者,來自台灣的黃士傑,解密幕後致勝關鍵,靠的不只是電腦運算,竟然是結合人類直覺般的思考模式!
人工智慧公司DeepMind資深研究員 黃士傑:「 (圍棋)大概有10的360次方的盤面,所以就是,你如果要用電腦去報窮舉的話,幾億年可能都窮舉不完,因為圍棋,它除了計算之外,它還是個直覺。」
AlphaGo觀察學習人類上千上萬種下棋棋譜,以「策略網路」研判最有可能勝出的20種下棋套路,在以「子網路」研判每一步可能的獲勝勝率,從而大幅減少搜尋可能。
人工智慧公司DeepMind資深研究員 黃士傑:「 策略網路就是減少搜尋的廣度,因為它只要想,從360步只要想20步 就好了,然後子網路就是減少搜尋的深度。它就是日以繼夜一直自我在下,然後成長,下,成長,下,成長,從錯誤中學習。」
Google人工智慧團隊兩百人中,有四名來自台灣專家,還有多位類神經網路專家、社會心理學高手,與高階工程師,催生AlphaGo誕生。AlphaGo自己甚至每天跟自己對下,累積上百萬盤下棋經驗,大幅提高人工智慧發展進程。黃士傑說,下一步,Google人工智慧團隊,將朝向研究醫療以及機器人領域發展。
人工智慧公司DeepMind資深研究員 黃士傑:「應用在很多實際的問題上面,比如說醫療,比如說機器人,如果你讓它學了很多很多人的病例,醫學的資料,這個資料,然後你現在有個新的病人,它的系統就能判斷出,大概是甚麼問題。」
人工智慧當然也不是萬能,AlphaGo在第四回合的對決中,出現如初學者般的重大失誤,如果情境隨時變換,人工智慧未必有好表現,但不可否認AI人工智慧的重大進展,將可能席捲各行各業。
新唐人亞太電視 高健倫 沈唯同 台灣台北報導
相關新聞
-

Google叛國遭中共滲透? 川普:司法部調查!
2019-07-17 20:29:43再來關心,美國總統川普,要求美國司法部調查Google是否已被中共情報單位滲透。原因是日前,億萬身價的科技投資人彼得提爾(Peter Thiel)指控 Google 與北京政府合作,認為 Google 應該以叛國罪 接受調查。
-
全面監控! 外媒實訪:AI 頭環走入中國小學
2019-09-24 21:20:21有中國的小學,聲稱是為了提高成績,讓學生戴上監測腦電波的AI頭環,以便即時反映學生的專注力,同步報告給老師和家長。《華爾街日報》記者走訪上海一所小學,實地觀察小學生的生活,如何被AI改變。
-
和碩迎接AOE時代 AI機器人新品打頭陣
2018-06-08 21:25:56國內組裝代工廠之一的和碩,宣布全面進軍人工智慧,今天由董事長童子賢帶頭,大規模展示新品,秘密打造的全方位家用機器人,還有具備保全和定位能力的商務機器人,都是首次亮相,童子賢認為,AI將影響帶動電子產品發展,台灣更具備優勢。
-
這些職業 AI無法取代! 李開復開講解謎
2018-08-10 14:06:59前Google大中華區總裁,現任創新工場董事長李開復,昨天晚間,再度登台討論人工智慧問題,特別強調人工智慧,正面臨諸多挑戰,強調,有些帶動溫暖和情感的職業,是不會輕易被人工智慧所取代。
-
手機即時監控數據 交大團隊透過AI除蟲害
2018-07-24 22:01:27交通大學透過AI人工智慧,簡化農業科技的門檻,讓農友透過手機就可以即時監控各項數據,包括農作物生長情形,以及撒水、驅蟲和施肥,都辦的到。
-
衝刺AI!科技部攜手NVIDIA 打造AI超級電腦
2017-10-26 20:06:23人工智慧產業快速發展,也成為科技部主導下,台灣下一世代產業發展主軸,今天NVIDIA創辦人黃仁勳,正式宣布,將與科技部合作,在台灣打造AI超級電腦,尤其也將一同培養關鍵產業人才。
-
物聯網、人工智慧夯 中央大學發表多項成果
2017-10-26 09:07:28中央大學24日在新竹舉辦物聯網暨AI人工智慧成果發表會,邀請竹科管理局、科學園區廠商以及交通大學等單位參與,希望透過產學合作,推動物聯網產業創新研發 。
-
有圖沒真相?AI影片以假亂真 Deepfake成社會隱憂
2021-03-16 20:52:582017年問世的Deepfake深偽影像,能將一個人的面容換到另一個人的臉上,移花接木製作出當事人不曾說過的話與行為的影片,不少類似的AI技術也逐步出現在市面上。不過這項技術背後存在的隱憂,也讓社會開始省思,這項技術是否該被禁止。
-
美科技廠來台布局AI 專家:比中國更優勢
2018-04-06 13:02:31富比世報導美國大型科技公司,像是谷歌、微軟和IBM,近期不約而同來到台灣大舉徵才,拓展AI產業版圖,專家學者就分析,儘管對岸資金充沛,但台灣發展AI產業,最重要的大數據、雲端運算,明顯比中國更具優勢。
-
AI語音助理太逼真 Google:將表明「是AI」
2018-05-12 21:15:49人工智慧被廣泛的運用,但也引發爭議,帶您看到,在今年的Google開發者大會上,公布了最新的語音助理技術。在現場示範的影片中,AI語音助理從聲音到反應都像真人一般自然,讓全場驚艷。不過這樣的技術也引起道德爭議。Google今天表示,未來將會口頭告知,確保通話的另一方了解,正在與AI對話。
-
宏碁毛利率創13年新高 轉型奏效進軍AI
2017-12-21 21:27:29再來看到,筆電大廠宏碁,今天舉辦年終記者會,董事長陳俊聖公布今年前三季毛利率為10.7%,創下13年來新高,宏碁轉型奏效,不僅轉虧為盈,還布局新領域,陳俊聖表示,在人工智慧方面,將積極拓展智慧城市業務。
-
科技抗疫成功關鍵 杜奕瑾:台灣展現AI軟實力
2020-03-19 13:25:04台灣在中共肺炎疫情中,科技產業軟實力被國際看到,PTT創辦人杜奕瑾就表示,像是推動口罩實名制,還有催生病毒用藥,展現台灣軟體人才和硬體能力,科技部三年前啟動人工智慧科研戰略計畫,打造出兩千多位轉業領域人才,效應也逐步深入到各領域。
-
日本無人自駕巴士 東京市中心試行
2018-01-06 02:55:59為改善交通安全與便利性,全球已有不少國家正研究無駕駛運用的可能性。日本近年來也積極導入無人自動駕駛交通工具,以解決人力不足的問題,同時還可節省人事及運輸成本。日前,無人駕駛的公車已在東京市區試行,到底可行不可行?一上路就知道!
-
工研院攜手帆宣、佳世達 展示AI落地智慧製造
2020-10-14 13:19:03美中科技戰,外加中共肺炎疫情衝擊,2020成為台灣產業數位轉型重要一年,實際上不少MIT技術,已經導入業界,工研院周三舉行技術交流會,攜手知名設備業者,包括帆宣,還有佳世達,展出智慧製造、商務、醫療各項應用,一起來看。
-
AI取代老師?賴揆:填鴨式教育將不存在!
2017-12-18 20:24:55再來看到,人工智慧時代來臨,行政院長賴清德,今(18)天出席一場「擁抱AI」的教育基金會年會活動時表示,這是個前瞻性的題目,他認為人工智慧,將對教育產生革命性的影響,過去填鴨、機械式的教育,將不存在,老師若只傳遞現有知識,恐怕也會被取代。
-
換臉假影片流竄!學者憂淪為操縱民意工具
2019-08-06 21:06:23好的觀眾朋友,如果今天您在網路上看到了一段影片中,出現了你的影像,但是內容卻不是你曾經說過的話,你的反映會是如何呢?近年來有一項AI「換臉」技術,製造出了不少假影片,讓不少公眾人物甚至一般民眾都深受其害。而隨著美國總統大選即將到來,各界擔憂,這項技術很有可能淪為操縱民意的工具。
-
社媒封殺.FB爭議多 馬斯克槓祖克柏挑戰數位霸權
2021-01-16 21:34:57現在有輿論質疑,1月6號衝擊國會大廈的抗議者,使用的是谷歌旗下的YouTube、臉書以及其它平台。而因為社群平台所扮演的角色受到質疑,谷歌和臉書目前是陷入被動之勢,紛紛發聲明解釋,事件也引發全球首富馬斯克,再次槓上臉書,在1月6號國會事件隔天,馬斯克,在推特上發出一張梗圖,暗諷臉書是國會衝擊事件的元凶。其實,這不是馬斯克和祖克柏第一次針鋒相對。
-
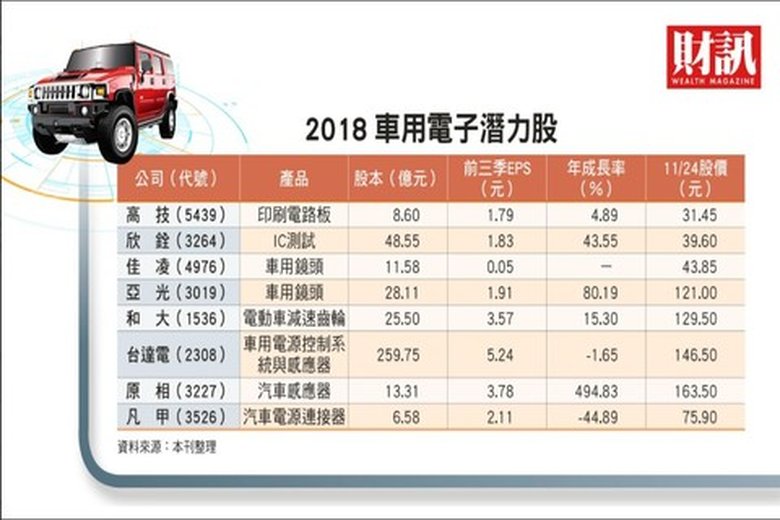
投資必備ABCDE 車用電子潛力股大趨勢
2017-11-30 19:32:12《財訊》雙週刊針對「2018投資大趨勢」製作專題報導,新年度投資配置「ABCDE科技概念」,建議以「ABCDE」為主軸投資含金量最高,A(AI,人工智慧)、B(Big Data,大數據)、C(Cloud,雲端運算)、D(3D感測)、E(Automobile Electronic,汽車電子),科技應用入侵各產業,新科技正取代舊科技,明年有五大科技趨勢值得投資人重視。2018年還是新科技大展身手的時刻,掌握5大科技趨勢,將是搶賺科技財神股的財富大好機會。
-
AI教父旋風來台 黃仁勳:AI將引爆巨變
2017-10-26 21:16:30有AI教父稱號的 NVIDIA執行長黃仁勳這個月來台。就為了兩件大事,一個是出席台積電30周年慶,另外,就是NVIDIA一年一度的 GTC 技術大會今天在台北登場,黃仁勳現場展示最新人工智慧應用開發平台。
-
美擬管制14類新興技術出口 斷中國製造2025?
2018-11-20 07:55:24美國商務部工業安全署19日發佈出口審查管制框架,列出14類領域,向公眾徵詢意見。包括,生物技術;人工智慧和機器學習技術;定位、導航和定時技術等等,外界認為這可能是要斷中國製造2025生路。